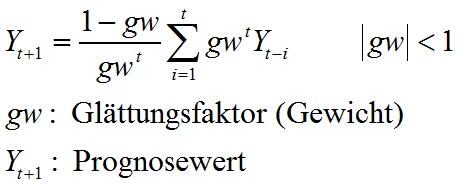Zeitreihenanalyse-Beispiele mit R
|
|||||||
Zeitreihenanalyse-Beispiele mit R | |||||||
Die hier verwendete Beispiel-Datei Zeitreihe_Getreide.csv beinhaltet 191 Bobachtungen und stammt vom Statistischen Bundesamt. Die Datei Zeitreihe_Getreide.csv ist ein Auszug und dient als Beispiel-Datei: >
Getreide <- read.csv2("Zeitreihe_Getreide.csv") Über die Funktion ts() wird die Variable Getreide in ein Zeitreihen-Objekt (Time-Series...) gewandelt: > GetreideIndex <- ts(Getreide$Preisindex, freq = 12,
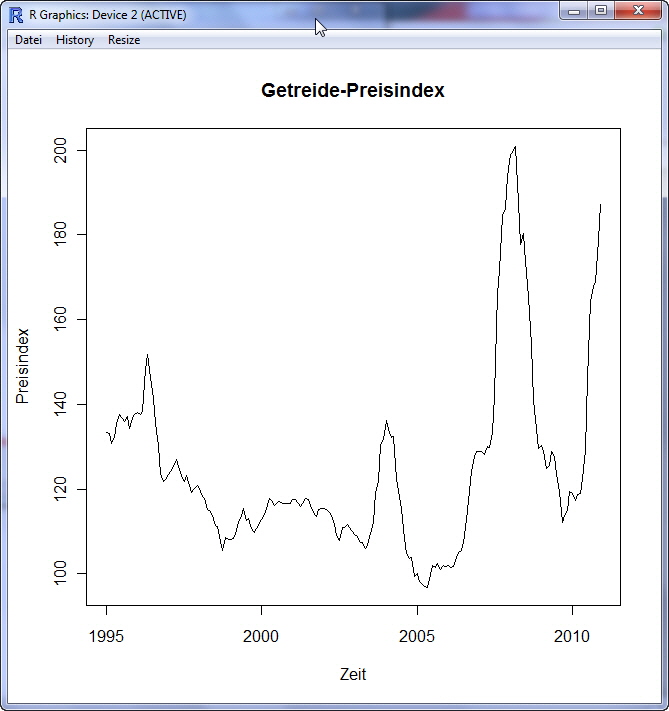
start = 1995) Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec Wie Sie oben erkennen können, wurde als Startpunkt 1995 (start = 1995) gewählt. Da jede Beobachtung für einen Monat steht, wurde die Jahreseinteilung auf 12 Monate (freq = 12) festgelegt. Verschaffen wir uns einen grafischen Überblick: > plot(GetreideIndex, main = "Getreide-Preisindex", xlab = "Zeit", ylab = "Preisindex")
In obiger Abbildung sind deutliche Schwankungen und Spitzen zu erkennen. Auch wenn ein lineares Modell aufgrund obiger Grafik nicht das optimale Modell ist, fangen wir trotzdem bei unserer Zeitreihenanalyse mit diesem Modell an! Dazu erstellen wir einen Vektor t über die Anzahl der Beobachtungen (1 bis 192 Monate) in dem Zeitreihenobjekt GetreideIndex: > t <- 1:length(GetreideIndex)
Das lineare Modell wird über die Parameter GetreideIndex und t geschätzt: > Linear <- lm(GetreideIndex ~ t)
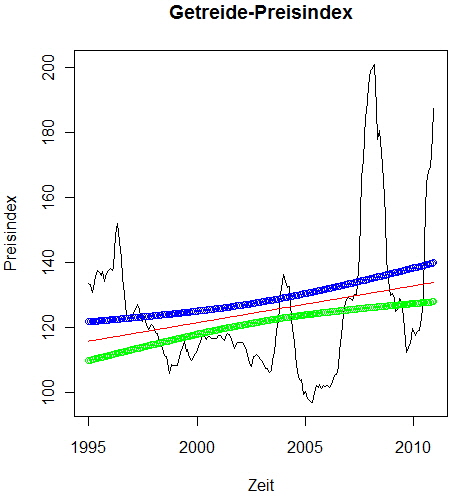
Call: Residuals: Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 115.55472 3.05700 37.800 < 2e-16 *** --- Residual standard error: 21.1 on 190 degrees of freedom Wie schon vermutet, ist die Anpassung für das lineare Modell Getreide-Preisindex= 115,55 + 0,0948 * t mit dem Gütemaß Multiple R-squared: 0.05909 nicht überragend! Schauen wir uns die Anpassung des Modells grafisch an! Dazu verwenden wir die Funktion predict und zur visuellen Beurteilung der Modellgüte lassen wir den Vertrauensbereiches mit P=95% (level = 0.95) mit schätzen: > Linear_P <- predict(Linear, int="c", level = 0.95) Zuerst stellen wir wieder die Grafik Getreide-Preisindex ..., > plot(GetreideIndex, main = "Getreide-Preisindex", xlab = "Zeit", ylab = "Preisindex") … dann die Schätzung (Anpassung, fit) des Preisindexes (abgelegt in Linear_P[,1], dargestellt in rot), ... > lines(ts(Linear_P[,1], freq = 12, start = 1995), col = "red") … und anschließend den unteren Vertrauensbereich (Linear_P[,2], grün) mit ... > lines(ts(Linear_P[,2], freq = 12, start = 1995), col = "green", type="p") ... und den oberen Vertrauensbereich (Linear_P[,3], blau) mit ... > lines(ts(Linear_P[,3], freq = 12, start = 1995), col = "blue", type="p") ... dar:
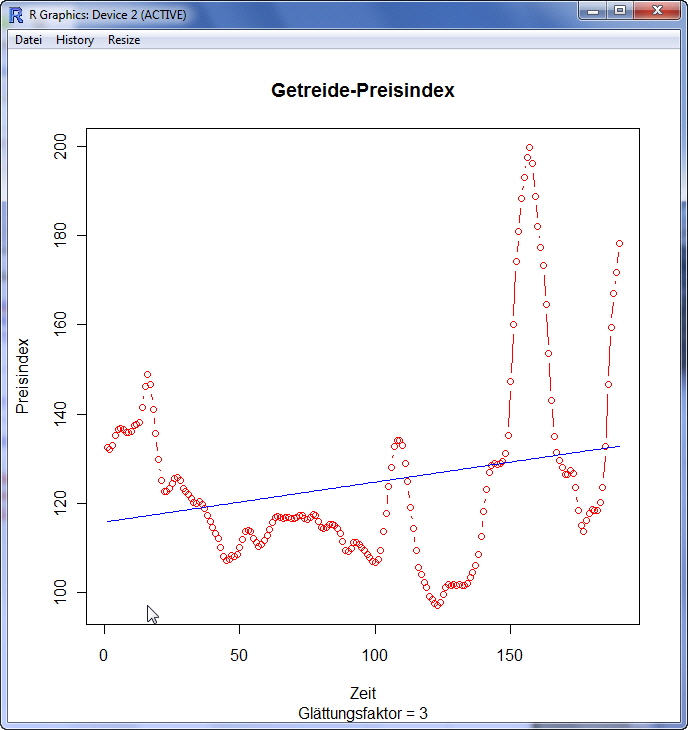
Die obige Grafik spricht für sich! Das lineare Modell ist nicht geeignet, um Vorhersagen für Zeitreihen wie abgebildet machen zu können. Vielleicht wird das lineare Modell besser, wenn wir versuchen, die extremen Bobachtungen zu glätten (oder auch filtern genannt). Für das nächste Beispiel wird die Methodik des gleitenden Durchschnitts angewendet. Dazu nutzen wir aus dem Paket zoo die Funktion rollmean(): > Glaetungsfaktor <- 3 # 3 Beobachtungen werden zu einem Wert gemittelt > length(Getreide$Preisindex)
> length(Getreide_g3) Nach der Glättung über 3 Beobachtungen ist der Getreide_g3-Vektor erwartungsgemäß um 2 Beobachtungen reduziert. Führen wir für die geglätteten Getreidedaten die Regressionsanalyse nach bekanntem Modell durch: > t_g3 <- 1:length(Getreide_g3) Call: lm(formula = Getreide_g3 ~ t_g3) Residuals: Coefficients: Residual standard error: 20.57 on 188 degrees of freedom Auch hier geben wir das Modell wieder grafisch aus: > plot(Getreide_g3, main = "Getreide-Preisindex", sub = "Glättungsfaktor = 3", xlab =
"Zeit", ylab = "Preisindex", type = "b", col = "red")
Die lineare Funktion ist durch das Glätten nicht besser geworden. Exponentielles Glätten (Holt-Winters) Eine weitere Glättungsmöglichkeit ist das exponentielle Glätten. Hierbei wird über Parameter gesteuert, mit welchem Gewicht aktuelle Beobachtungen in das Modell einfließen und welches Gewicht den älteren Beobachtungen zugestanden wird. Eine derartige Glättungsfunktion ist die Holt-Winters-Funktion (in R: HoltWinters()). Bevor wir uns mit dieser Funktion beschäftigen, schauen wir uns die Funktion decompose() an. Ungeachtet der linearen Modell-Güte ist eine saisonale Komponente in der Zeitreihe Getreide-Preisindex visuell nicht zu erkennen. Deswegen wird erwartet, dass die R-Funktion decompose() die die Zeitreihen in die Trend, Saison und irreguläre Komponente (Restkomponente) zerlegt, kein Resultat liefert: > Zerlegung <- decompose(Getreide$Preisindex)
Unsere Erwartung wurde bestätigt. Kommen wir zurück zum exponentiellen Glätten unter Verwendung der Holt-Winters-Funktion. Die Idee, die hinter der exponentiellen Glättung steht, ist besonders für ökonomische Zeitreihen einsichtig: Ist es sinnvoll, allen Beobachtungen der Zeitreihe das gleiche Gewicht einzuräumen, oder ist es sinnvoller jüngeren Beobachtungen mehr Gewicht als älteren Bobachtungen einzuräumen? Wenn Sie für Ihre Zeitreihe diesem Gedanken zustimmen können, ist die Methodik des exponentiellem Glättens wahrscheinlich die Richtige für Sie! In dieser Methodik werden die Gewichte der Beobachtungen mit jeder neu hinzukommenden Beobachtung exponentielle abgewichtet“:
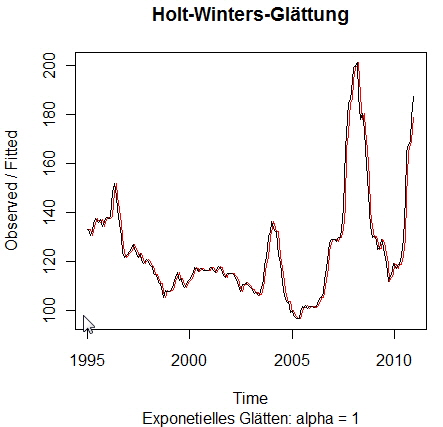
Ändern sich die Beobachtungen langsam, sollte gw groß gewählt werden. Dadurch werden die Beobachtungen etwa gleich gewichtet. Ändern sich die Beobachtungen hingegen schnell, sollte gw klein gewählt werden. Dadurch liegt das Gewicht bezüglich der Beobachtungen in der Zeitreihe auf den jüngsten Beobachtungen. Für eine große Anzahl Beobachtungen kann in obiger Formel der Term wt unberücksichtigt bleiben, sodass sich als Prognosefunktion für das einfache exponentielle Glätten ergibt. Dieses Prognoseverfahren wird auch als adaptives Prognoseverfahren bezeichnet. Die Herausforderung dieser Methodik ist das Schätzen des Glättungsfaktor gw! Schauen Sie sich die Hilfe in R zur Funktion HoltWinters() an, hier wird die Umsetzung des exponentiellen Glättens beschrieben! Im ersten Anwendungsbeispiel führen wir nur das exponentielle Glätten durch: > HW <- HoltWinters(GetreideIndex, alpha = 1, beta = F, gamma = F)
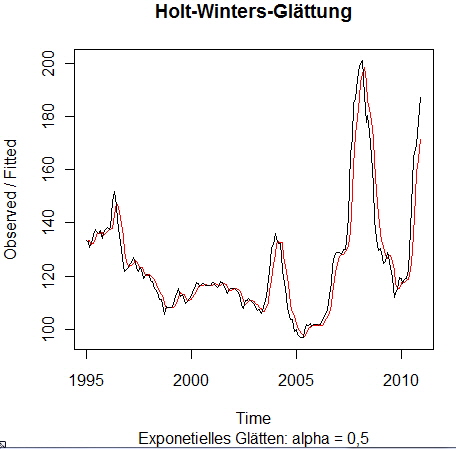
Das Argument alpha legt nur den exponentiellen Glättungsfaktor fest. Die R-Ausgabe des Modells macht uns darauf aufmerksam (without trend) und deswegen wird auch nur der letzte Wert a des Modells, vergleichbar mit dem Prognosestartwert oder dem Schnittpunkt der Y-Achse, ausgegeben (Coefficients): Holt-Winters exponential smoothing without trend and without seasonal component. Call: Smoothing parameters: Coefficients: Eine Veränderung von alpha macht sich durch einen deutlich glatteren Darstellungsverlauf bemerkbar (roter Kurvenverlauf): > HW <- HoltWinters(GetreideIndex, alpha = 0.5, beta = F, gamma = F)
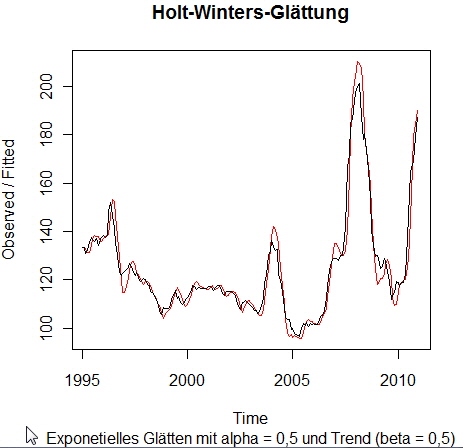
Das dazugehörige Modell: Holt-Winters exponential smoothing without trend and without seasonal component. Call: Smoothing parameters: Coefficients: Wie gehen von der Annahme aus, dass unsere Getreide-Zeitreihe frei von einer Session-Komponente ist (gamma = F). Deswegen werden wir das Holt-Winters-Modell nur auf die Trendkomponente b über die Ausprägung des Arguments beta ausdehnen: > HW <- HoltWinters(GetreideIndex, alpha = 0.5, beta = 0.5, gamma = F) Holt-Winters exponential smoothing with trend and without seasonal component. Call: Smoothing parameters: Coefficients: Die Anpassung des Modells (roter Kurvenverlauf) im Vergleich zu der beobachteten Zeitreihe (schwarzer Kurvenverlauf) sieht wie folgt aus:
Das Vorhersagemodell Holt-Winters ohne Saison-Komponente ist folgende lineare Funktion (die Glättung wurde berücksichtigt, siehe R-Hilfe-Funktion zu Holt-Winters): Y t+1 = a + b * t
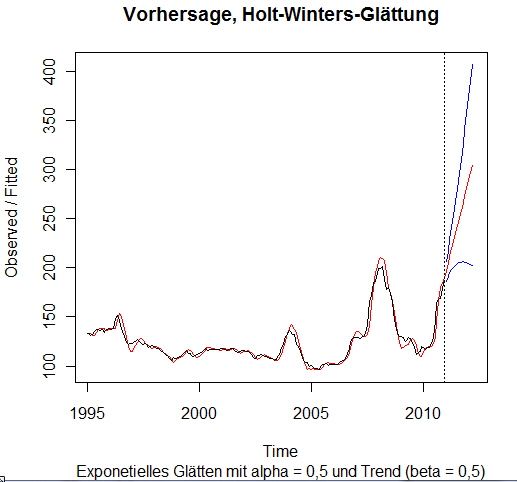
Machen wir über die predict()-Funktion eine Vorhersage auf Basis obigem Modell für 15 Zeitschritte (Argument n.ahead = 15, Ausgabe des Vertrauensbereiches für P = 95%) in die Zukunft und lassen uns diese grafisch anzeigen: > HW_P <- predict(HW, 15, prediction.interval = T)
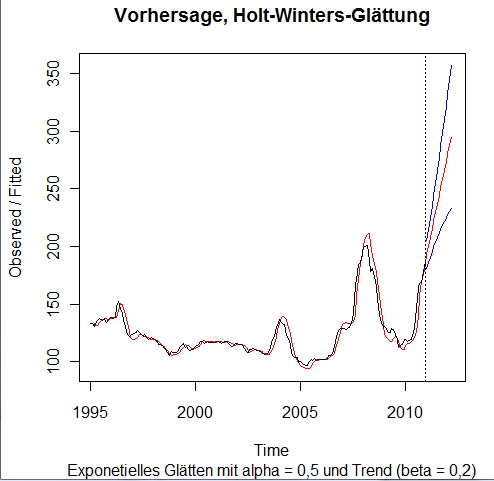
Ab der gestrichelten Linie in obiger Grafik wird die Prognose (rot) und der Vorhersage-Intervall (blau) angezeigt. Die Güte der Prognose ist von der Wahl der Parameter alpha für die Glättung des Niveaus (Parameter a, Startpunkt der Prognose) und beta (Parameter b, Glättung des linearen Trends) abhängig. Die Schätzung der Prognose lässt sich natürlich auch numerisch ausgegeben (fit: Prognose, upr/lwr: Vorhersage-Intervall): > HW_P fit upr lwr Hier die grafische Darstellung eines Beispiels für beta = 0,2...
… auf Basis dieser Modell-Parameter: Holt-Winters exponential smoothing with trend and without seasonal component. Call: Smoothing parameters: Coefficients: Und hier die Vorhersage-Werte mit Vorhersage-Intervall: > HW_P fit upr lwr Der Einfluss, insbesondere des beta-Parameters, ist deutlich zu erkennen. Visuell und durch die dargestellten numerischen Vorhersagedaten wird der Eindruck erweckt, die Güte der Vorhersage ist durch die Wahl beta = 0,2 im Vergleich zu beta = 0,5 erheblich gesteigert worden. Wird fortgesetzt!
| |||||||||||||
Hat der Inhalt Ihnen weitergeholfen und Sie möchten diese Seiten unterstützen? |